原因
Tcp通过四次挥手关闭tcp连接。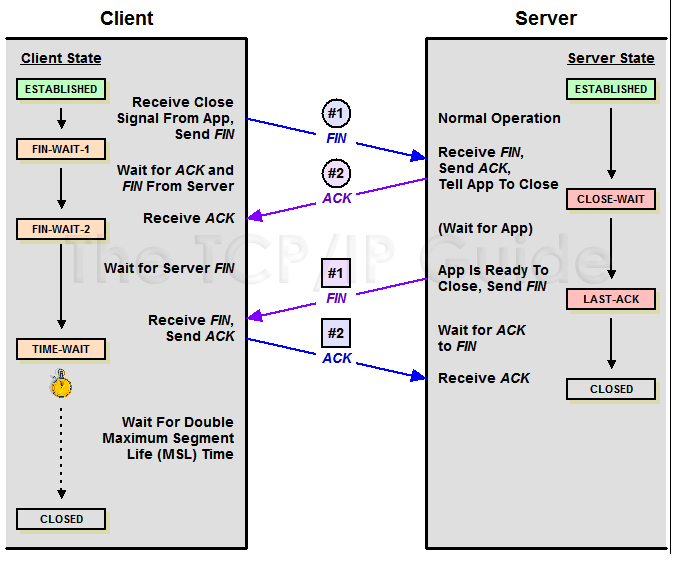
作为主动关闭连接的一方在接收到被动方发送的fin之后,需要向其发送ack,被动方接收到ack后才会关闭连接,在这个过程中主动方需要等待2个msl(也就是你说的包的最大生命周期)的时间去确保被动方收到ack,因为在被动方没有收到ack超时后,会重新发送fin到主动关闭方,主动方也会继续发送ack到被动方。由于nginx是短连接,所以每次请求都需要建立与关闭tcp连接,nginx在调用后端接口时,又是主动关闭方,所以才会造成大量的TIME_WAIT。
相关知识:
穿插一点MSL的知识:MSL指的是报文段的最大生存时间,如果报文段在网络活动了MSL时间,还没有被接收,那么会被丢弃。关于MSL的大小,RFC 793协议中给出的建议是两分钟,不过实际上不同的操作系统可能有不同的设置,以Linux为例,通常是半分钟,两倍的MSL就是一分钟,也就是60秒,并且这个数值是硬编码在内核中的,也就是说除非你重新编译内核,否则没法修改它。
为什么主动关闭的一方不直接进入CLOSED状态,而是进入TIME_WAIT状态,并且停留两倍的MSL时长呢?这是因为TCP是建立在不可靠网络上的可靠的协议。例子:主动关闭的一方收到被动关闭的一方发出的FIN包后,回应ACK包,同时进入TIME_WAIT状态,但是因为网络原因,主动关闭的一方发送的这个ACK包很可能延迟,从而触发被动连接一方重传FIN包。极端情况下,这一去一回,就是两倍的MSL时长。如果主动关闭的一方跳过TIME_WAIT直接进入CLOSED,或者在TIME_WAIT停留的时长不足两倍的MSL,那么当被动关闭的一方早先发出的延迟包到达后,就可能出现类似下面的问题:
旧的TCP连接已经不存在了,系统此时只能返回RST包
新的TCP连接被建立起来了,延迟包可能干扰新的连接
不管是哪种情况都会让TCP不再可靠,所以TIME_WAIT状态有存在的必要性。
解决方案
关于linux的方案
- 通过增大自动分配的端口数量缓解socket不足。
通过命令 sysctl -a | grep local_port_range 可以查看当前系统中可以自由分配的端口范围。
net.ipv4.ip_local_port_range = 32768 61000
我们发现可用的端口数量大概在30000左右。
通过命令 sysctl net.ipv4.ip_local_port_range=”10240 61000”
可以将端口范围扩大。但是这种方案只能缓解TIME_WAIT的问题。 - 通过修改ip_conntrack 模块
ip_conntrack:顾名思义就是跟踪连接。一旦激活了此模块,就能在系统参数里发现很多用来控制网络连接状态超时的设置,其中自然也包括TIME_WAIT:
shell> modprobe ip_conntrack
shell> sysctl net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait
我们可以尝试缩小它的设置,比如十秒,甚至一秒,具体设置成多少合适取决于网络情况而定,但是ip_conntrack引入的问题比解决的还多,比如性能会大幅下降,所以不建议使用。
- tcp_tw_recycle 和 tcp_timestamps
激活tcp_tw_recycle来加快TIME_WAIT的回收,使用这种方式,time_wait的数量减少的非常明显,但是使用这种方式会引发一些风险。
An additional mechanism could be added to the TCP, a per-host cache of the last timestamp received from any connection. This value could then be used in the PAWS mechanism to reject old duplicate segments from earlier incarnations of the connection, if the timestamp clock can be guaranteed to have ticked at least once since the old connection was open. This would require that the TIME-WAIT delay plus the RTT together must be at least one tick of the sender’s timestamp clock. Such an extension is not part of the proposal of this RFC.
服务器会缓存每个主机的最新时间戳,后续请求中如果时间戳小于缓存中的时间戳,就会discard这些请求。
在NAT环境中,所有处于同一局域网的主机都被服务器视为同一个ip,也就意味对于服务器来说,在同一个局域网中的客户机都是同一个客户机,而事实上,这些客户机的时间戳是会有差异的,最终就导致一些请求被丢弃。
- tcp_tw_reuse
激活tcp_tw_reuse来复用TIME_WAIT连接,具体来说就是当创建新的连接时,如果可能的话会考虑复用相应的TIME_WAIT连接。tcp_tw_reuse比tcp_tw_recycle要安全,因为TIME_WAIT创建时间必须超过一秒才可能被复用,第二只用连接的时间戳是递增的才可以复用。 这是一种比较可行的解决方案。
- tcp_max_tw_buckets
这个选项是用来设置最大TIME_OUT总数的,和ip_conntrack一样,使用这种方式也会引入其他的问题。
关于nginx的方案
Nginx从1.1.4开始,实现了对后端机器的长连接支持。可以通过修改配置,将Nginx与后端服务器的连接设置为长连接。
最终解决方案
目前我的解决方案:
nginx服务器上的tcp_tw_reuse设置为1,从而当nginx向后端服务器建立连接时会复用正在TIME_WAIT的端口。修改这一点后,我做了一系列测试(所有测试都以jmeter作为测试工具,线程数量500个,循环无限次),发现当tcp_tw_reuse在未被激活前,当请求总量到达9w左右的时候,TIME_WAIT的数量一直保持在32768(tcp_max_tw_buckets),当tcp_tw_reuse被激活时,TIME_WAIT数一直保持在32768以下,并当请求量超过10w后也没有请求出现超时。
后端服务器上的tcp_tw_recycle设置为1,由于nginx存在于内网中,所以不存在NAT造成的时间戳混乱,同时又加快了TIME_WAIT回收。经测试,激活前,后端服务器的TIME_WAIT数量大约在1w到2w之间波动,激活后,在2000到3000左右波动。