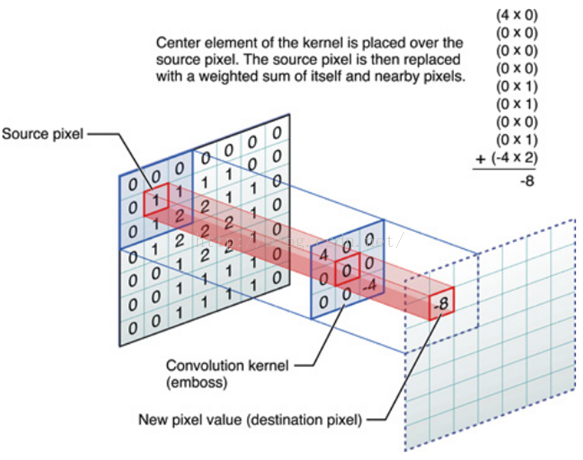
最近很多人问我词向量是怎么计算出来的,所以写一篇来解释一下。
什么是词向量?
词向量就是某一个多维向量能唯一代表某一个词。
举个例子:假设中文只有4个词【你、我、他、它】,如果用0或1去表示他们,【你】可以表示为(1,0,0,0),【我】可以表示为(0,1,0,0),以此类推。
这些0或1组成的向量就可以称之为词向量,但是这种模式的词向量并不好,主要原因有两点:第一中文中有非常多的词,如果每一个词就占一位,那么这样的词向量就会非常长,
同时如果添加了新的词汇,向量的维度就需要增加。第二这些词向量永远都是有一个唯一的1,其余都是0,这样的词向量只能代表这个词,但是不能代表这个词的意思,每个向量之间都是正交。
所以以上述onehot方式编码的向量,并没有什么意义。
为了解决上述这个问题呢,Mikolov就提出了一种模型叫Word Embeddings,这种模型可以把词投射到一个固定的多维空间,
每个词的词向量都是同样的长度且相近语义的词会聚集在一起。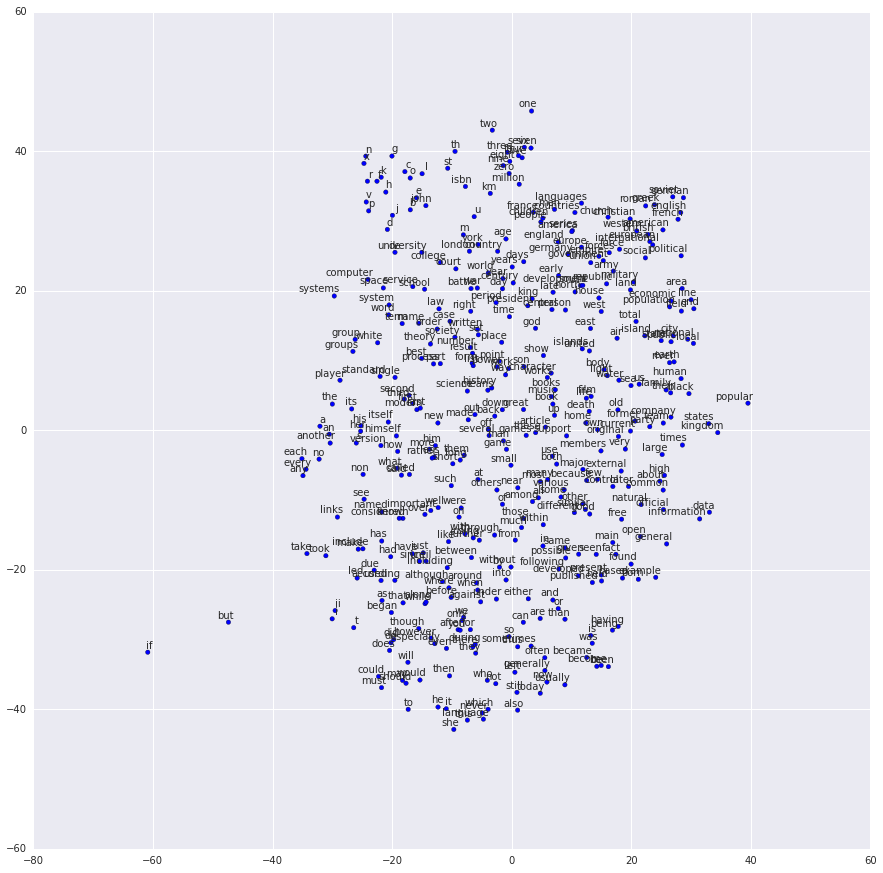
实现这种模型,又分两种主流的方法,一个叫Continuous Bag-of-Words model(CBOW),一个叫skip-gram。
CBOW
CBOW认为一个词的语义可以通过其周边的词来表示,所以通过周边的词来预测被选词。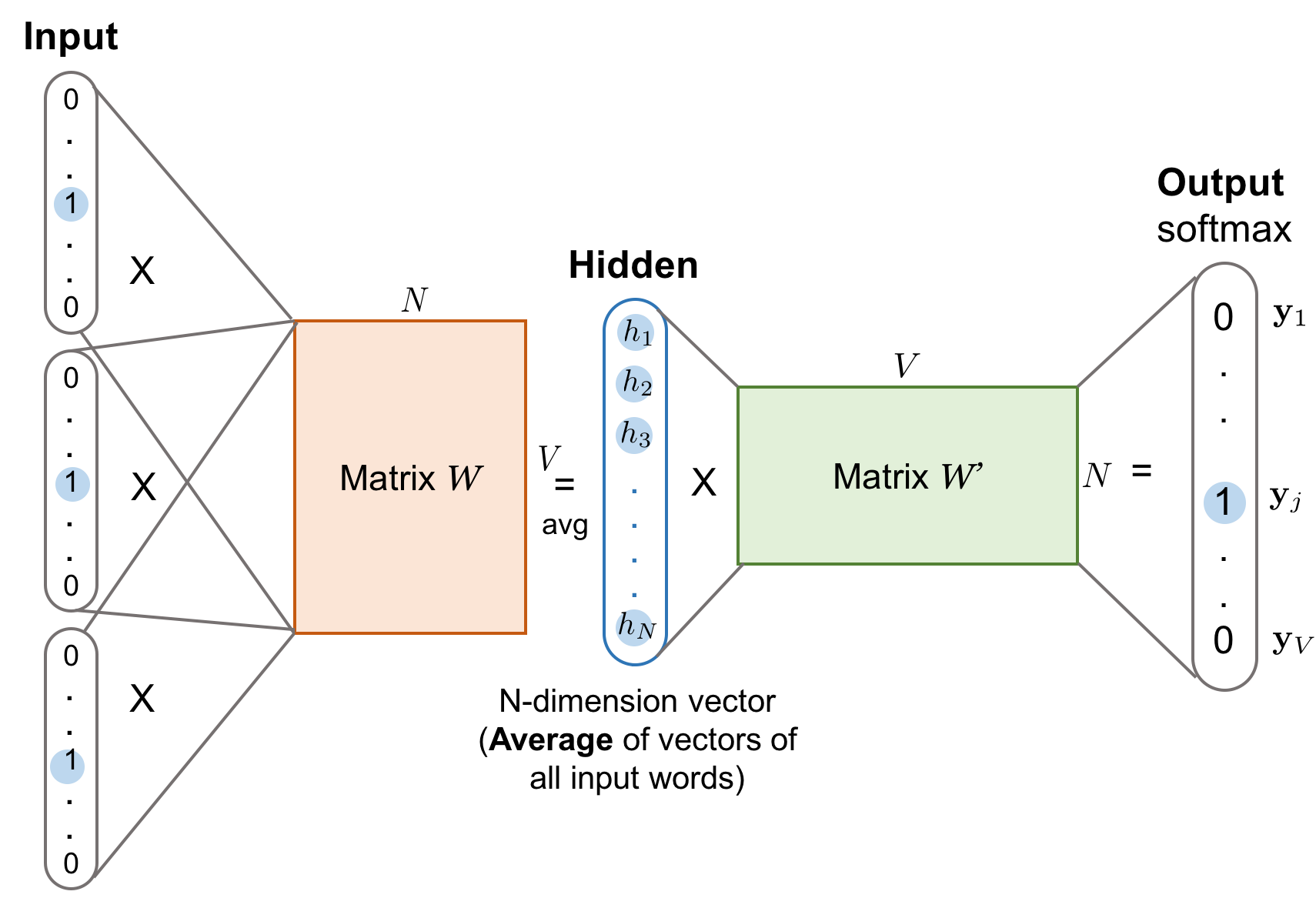
这张图其实完整的描述了cbow的全部过程,但是并不好理解,所以我用一个例子一步一步解释这张图
假设在世界上只有一个句子”I love you”, 也就是说只有三个单词(用大写的V表示,V=3),通过onehot编码的方式,I可以表示为(1,0,0), love可以表示为(0,1,0), you可以表示为(0,0,1)。
cbow用周边n个词预测中间的词,假设n=1,我们的模型要通过(I,you)预测出love。
- 将I(1,0,0)和you(0,0,1)输入输入层,由于n=1,所以输入层由两个神经元组成。
- 每个输入向量乘以一个V*N的矩阵,V是上面说的词库的大小,在这里就是3,N则是隐藏层神经元的个数。
- 因为输入向量是一个1V的矩阵,所以相乘后的结果是一个1N的矩阵。
- 把所有的输入向量产生的乘积累加之后取平均值得到一个新的1*N的矩阵就是我们在隐藏层的输出。
- 把这个输出的向量再乘以一个NV的矩阵(与上述VN的矩阵没有任何关系),又会得到一个1*V的矩阵,可以把这一层叫做投影层,这层的作用就是把隐藏层的结果再映射到词库里。
- 我们把最终得到的1*V的矩阵通过softmax得到矩阵中最大概率的那个列,而这一列就应该对应love这个单词,如果不是,说明我们的隐藏层和投影层的矩阵并不符合要求。
- 我们通过cost function(代价函数)以及向后传播算法(这部分内容主要涉及神经网络,有兴趣可以自行查阅)去不断调整这两个矩阵的参数,直到其到达一个我们相对满意的程度。这就是训练模型的过程。
- 当这个模型达到一定的准确率后,我们通过每个词的onehot编码乘以隐藏层的矩阵得到的1*N矩阵,就是我们要得到的这个词的词向量了,所以隐藏层神经元的个数就决定了词向量的维度。
Skip-Gram
不同于CBOW,Skip-Gram模型通过选中词预测周围n个词。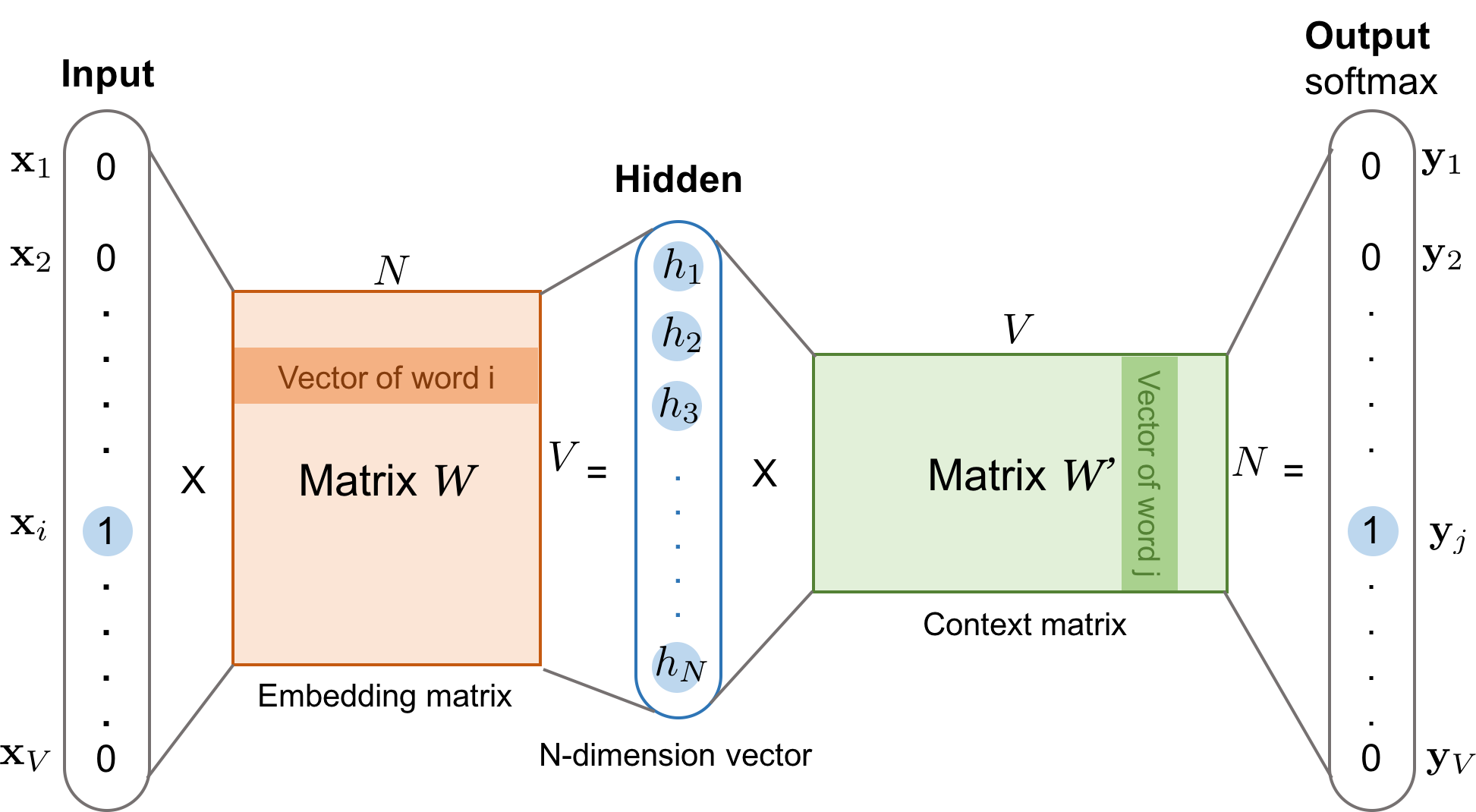
还是按照CBOW的例子,在Skip-Gram模型下,当n=1时,我们的模型需要通过love预测出I和you。
Skip-Gram的训练过程基本与CBOW相同,唯一的区别就是CBOW需要输入向量是多个,需要把隐藏层的结果累加取平均值,
而Skip-Gram则不需要,直接计算就好。
工具
开源的词向量工具有很多,这里推荐两个
- facebook开源的fasttext,这个项目已经实现了算法,使用者只需要准备数据和调整参数即可,训练速度很快,很好用。
- tensorflow google开源的神经网络框架,可以再tutorial里自行搜索词向量相关的例子,可以实现自己的词向量算法。